
How many discoveries are right under our noses,
if only we cross-referenced the right data sets?
Convergence of Multiple “Thought Streams”
Yeah, I love quoting movies. And tv shows. And song lyrics. But it’s not the quoting that I enjoy – it’s the connection. Taking something technical, for instance, and spotting an intrinsic similarity in something completely unrelated like a movie – I get a huge kick out of that.
That tendency to make connections kinda flows through my whole life – sometimes, it’s even productive and not just entertaining ![]()
Anyway, I think I am approaching one of those aha/convergence moments. It’s actually a convergence moment “squared,” because it’s a convergence moment about… convergence. Here are the streams that are coming together in my head:
1) “Expert” thinking is too often Narrow thinking
I’ve read a number of compelling articles and anecdotes about this in my life, most recently this one in the New York Times. Particularly in science and medicine, you have to develop so many credentials just to get in the door that it tends to breed a rigid and less creative environment.
And the tragedy is this: a conundrum that stumps a molecular cancer scientist might be solvable, at a glance, by the epidemiologist or the mathematician in the building next door. Similarly, the molecular scientist might breeze over a crucial clue that would literally leap off the page at a graph theorist like my former professor Jeremy Spinrad.
2) Community cross-referencing of data/problems is a longstanding need
Flowing straight out of problem #1 above is this, need #2. And it’s been a recognized need for a long time, by many people.

Swivel and ManyEyes Both Were Attempts at this Problem
I remember being captivated, back in 2006-2007, with a website called Swivel.com. It’s gone now – and I highly recommend reading this “postmortem” interview with its two founders – but the idea was solid: provide a place for various data sets to “meet,” and to harness the power of community to spot trends and relationships that would never be found otherwise. (Apparently IBM did something similar with a project called ManyEyes, but it’s gone now, too).
There is, of course, even a more mundane use than “community research mashups” – our normal business data would benefit a lot by being “mashed up” with demographics and weather data (just to point out the two most obvious).
I’ve been wanting something like this forever. As far back as 2001, when we were working on Office 2003, I was trying to launch a “data market” type of service for Office users. (An idea that never really got off the drawing board – our VP killed it. And, at the time, I think that was the right call).
3) Mistake: Swivel was a BI tool and not just a data marketplace
When I discovered that Swivel was gone, before I read the postmortem, I forced myself to think of reasons why they might have failed. And my first thought was this: Swivel forced you to use THEIR analysis tools. They weren’t just a place where data met. They were also a BI tool.
And as we know, BI tools take a lot of work. They are not something that you just casually add to your business model.
In the interview, the founders acknowledge this, but their choice of words is almost completely wrong in my opinion:

Check out the two sections I highlighted. The interface is not that important. And people prefer to use what they already have. That gets me leaning forward in my chair.
YES! People prefer to use the analysis/mashup toolset they already use. They didn’t want to learn Swivel’s new tools, or compensate for the features it lacked. I agree 100%.
But to then utter the words “the interface is not that important” seems completely wrong to me. The interface, the toolset, is CRITICAL! What they should have said in this interview, I think, is “we should not have tried to introduce a new interface, because interface is critical and the users already made up their mind.”
4) PowerPivot is SCARY good at mashups
I’m still surprised at how simple and magical it feels to cross-reference one data set against another in PowerPivot. I never anticipated this when I was working on PowerPivot v1 back at Microsoft. The features that “power” mashups – relationships and formulas – are pretty… mundane. But in practice there’s just something about it. It’s simple enough that you just DO it. You WANT to do it.
Remember this?
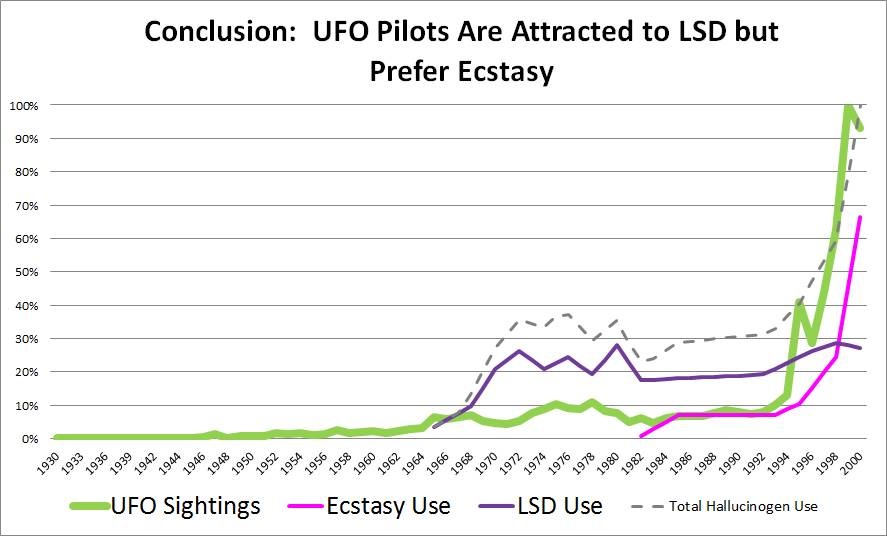
OK, it’s pretty funny. But it IS real data. And it DOES tell us something surprising – I did NOT know, going in, that I would find anything when I mashed up UFO sightings with drug use. And it was super, super, super easy to do.
When you can test theories easily, you actually test them. If it was even, say, 50% more work to mash this up than it actually was, I probably never would have done it. And I think that’s the important point…
PowerPivot’s mashup capability passes the critical human threshold test of “quick enough that I invest the time,” whereas other tools, even if just a little bit harder, do not. Humans prioritize it off the list if it’s even just slightly too time consuming.
Which, in my experience, is basically the same difference as HAVING a capability versus having NO CAPABILITY whatsoever. I honestly think PowerPivot might be the only data mashup tool worth talking about. Yeah, in the entire world. Not kidding.
5) “Export to Excel” is not to be ignored
Another thing favoring PowerPivot as the world’s only practically-useful mashup tool: it’s Excel.
I recently posted about how every data application in the world has an Export to Excel button, and why that’s telling.
Let’s go back to that quote from one of the Swivel founders, and examine one more portion that I think reflects a mistake:
![]()
Can I get a “WTF” from the congregation??? R and SAS but NO mention of Excel! Even just taking the Excel Pro, pivot-using subset of the Excel audience (the people who are reading this blog), Excel CRUSHES those two tools, combined, in audience. Crushes them.
Yeah, the mundane little spreadsheet gets no respect. But PowerPivot closes that last critical gap, in a way that continues to surprise even me. Better at business than anything else. Heck, better at science too. Ignore it at your peril.
6) But Getting the Data Needs to be Just as Simple!
So here we go. Even in the UFO example, I had to be handed the data. Literally. Our CEO already HAD the datasets, both the UFO sightings and the drug use data. He gave them to me and said “see if you can do something with this.”
There is no way I EVER would have scoured the web for these data sets, but once they were conveniently available to me, I fired up my convenient mashup tool and found something interesting.
7) DataMarket will “soon” close that last gap
In a post last year I said that Azure DataMarket was falling well short of its potential, and I meant it. That was, and is, a function of its vast potential much more so than the “falling short” part. Just a few usability problems that need to be plugged before it really lights things up, essentially.
On one of my recent trips to Redmond, I had the opportunity to meet with some of the folks behind the scenes.
Without giving away any secrets, let me say this: these folks are very impressive. I love, love, LOVE the directions in which they are thinking. I’m not sure how long it’s going to take for us to see the results of their current thinking.
But when we do, yet another “last mile” problem will be solved, and the network effect of combining “simple access to vast arrays of useful data sets” with “simple mashup tool” will be transformative. (Note that I am not prone to hyperbole except when I am saying negative things, so statements like this are rare from me.)
In the meantime…
While we wait for the DataMarket team’s brainstorms to reach fruition, I am doing a few things.
1) I’ve added a new category to the blog for Real-World Data Mashups. Just click here.
2) I’m going to do share some workbooks that make consumption of DataMarket simple. Starting Thursday I will be providing some workbooks that are pre-configured to grab interesting data sets from Data Market. Stay tuned.
3) I’m likely to run some contests and/or solicit guest posts on DataMarket mashups.
4) I’m toying with the idea of Pivotstream offering some free access to certain DataMarket data sets in our Hosted PowerPivot offering.
See you Thursday ![]()
